
This post is also available in .
Op televisie, in de krant en op internet kom je regelmatig grafieken tegen. Helaas is het lezen van grafieken niet altijd even makkelijk, en het kritisch beoordelen ervan al helemaal niet. Toch is dit cruciaal, omdat niet alle grafieken de data even eerlijk weergeven en ze je zo een vertekend beeld kunnen geven. Daarom in deze blog twee tips om beter te leren grafieklezen!
1. Let goed op de assen
Vaak als je een grafiek ziet, kijk je eerst naar de titel en het patroon dat je ziet in de grafiek, omdat die het belangrijkst lijken om de grafiek te kunnen begrijpen. Stel we kijken bijvoorbeeld naar de grafiek hieronder. Deze grafiek met data van het RIVM geeft aan hoeveel mensen positief getest zijn op corona op 3 november 2020. Voor de provincies Gelderland en Utrecht is het gemiddelde van de gemeentes in die provincies weergegeven. We kunnen uit de titel en grafiek opmaken dat er in Utrecht over het algemeen meer positieve testen waren dan in Gelderland. En zo in een eerste oogopslag, lijkt dit een vrij dramatisch verschil.
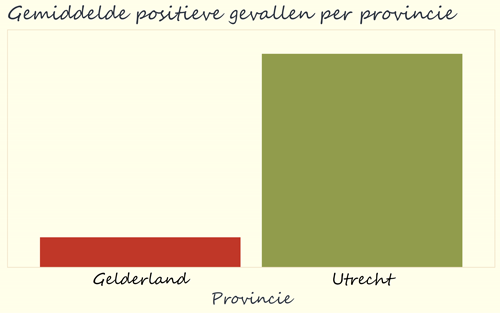
Hoewel uit deze grafiek duidelijk wordt dat er in Utrecht gemiddeld meer positieve testen waren, is het natuurlijk totaal niet duidelijk hoe groot dat verschil precies is. Om daarachter te komen, is het heel belangrijk om goed te kijken wat de hoogte van de blokken eigenlijk betekent. We moeten dus kijken naar de verticale as (ook wel y-as genoemd) om te zien welke waarden er precies worden afgebeeld.
Als we dat in de grafiek hieronder doen dan valt op dat er is ingezoomd. De gemiddelde aantallen positieve testen worden hier getoond op een as van 14 tot 20, waardoor het verschil tussen Gelderland en Utrecht groter lijkt dan het daadwerkelijk is.
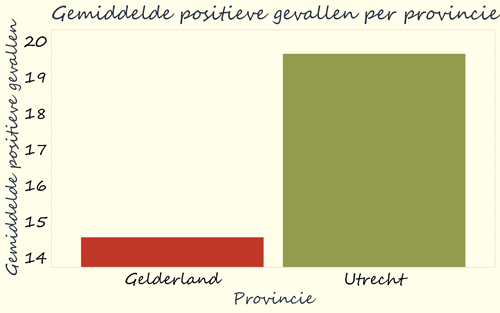
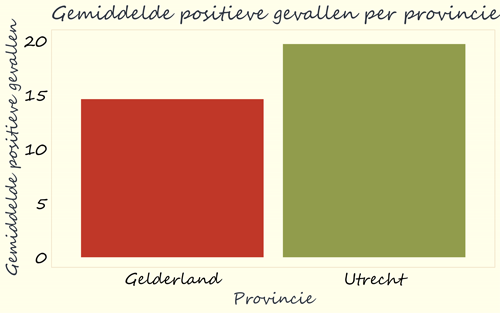
Als men de data eerlijker wil weergeven, kan het goed zijn om de waarden op de assen te laten beginnen bij 0. Het doel van deze grafiek is tenslotte het weergeven van getallen als de hoogte van een blok. Dan is het goed als de hoogte van het blok ook echt gerelateerd is aan de waarde. In dit geval is de waarde van Utrecht (19.6) ongeveer 1,3 keer zo hoog als de waarde van Gelderland (14.5). Dan is het eerlijk als het groene blok van Utrecht ook ongeveer 1,3 keer zo hoog is als het rode blok van Gelderland. Dat krijg je voor elkaar door de as vanaf 0 te laten beginnen.
Als we dat doen, zoals in de grafiek hieronder, dan is de eerste oogopslag heel anders: in plaats van een gigantisch verschil in hoogte tussen de twee blokken, zien we nu een kleiner verschil. Het is belangrijk om hier altijd goed naar te kijken, want door zo in te zoomen kan iemand verschillen groter laten lijken dan ze zijn. En door uit te zoomen, kan iemand verschillen juist kleiner laten lijken.
2. Wees op je hoede voor weggelaten informatie
In de grafiekjes hierboven zagen we alleen het gemiddelde afgebeeld in de hoogte van het blok. Dat is natuurlijk niet heel informatief: er had net zo goed een zin kunnen staan met “Het gemiddelde aantal positieve testen op 3 november was 14.5 in Gelderland en 19.6 in Utrecht”. Zonde, want een grafiek kan juist gemakkelijk meer informatie overbrengen – denk aan “één beeld zegt meer dan duizend woorden”.
Soms is het weglaten van informatie een manier om (met opzet of per ongeluk) de data anders weer te geven dan de werkelijkheid. We weten nu bijvoorbeeld niet hoeveel gemeentes zijn meegenomen per provincie. In het ergste geval zou het kunnen dat de maker van de grafiek bijvoorbeeld alleen de gemeente Oldebroek heeft meegenomen voor Gelderland en alleen de gemeente Zeist voor Utrecht.
Daarnaast weten we ook niet hoeveel variatie er is tussen de gemeentes binnen elke provincie. Als alle gemeentes in Utrecht ongeveer 20 nieuwe besmettingen telden en alle gemeentes in Gelderland ongeveer 15, dan zijn er in de Gelderse gemeentes inderdaad minder besmettingen dan in de Utrechtse. Maar als er veel overlap is tussen de getallen voor de Gelderse en Utrechtse gemeentes, dan is het gemiddelde verschil van 5,5 minder betekenisvol. We willen dus ook graag zien hoeveel variatie er is.
Daarom is er hieronder nog een grafiek, die maar liefst op twee manieren de data weergeeft. Elk gekleurd bolletje aan de linkerkant representeert een gemeente. De kleur en locatie van het bolletje geeft aan bij welke provincie die gemeente hoort, en de hoogte geeft aan hoeveel positieve tests er waren in die gemeente op 3 november. Zo zien we bijvoorbeeld dat er in Gelderland 11 gemeentes waren met 0-5 positieve tests (de onderste rij bevat 11 rode bolletjes), en in Utrecht 7. We zien ook dat er 51 rode bolletjes zijn en 26 groene, wat precies overeenkomt met het aantal gemeentes in Gelderland en Utrecht. Er zijn dus gelukkig meer gemeentes dan Oldebroek en Zeist meegenomen!

Aan de rechterkant zien we de verdeling van het aantal positieve testen per provincie op een iets andere manier. Hoe breder de vorm is, hoe vaker dat aantal positieve testen relatief voorkwam. We zien dat in zowel Gelderland als Utrecht getallen tussen de 0 en 40 het meest voorkwamen, want daar zijn de vormen het breedst. Als we zo die variatie kunnen zien, valt op dat Gelderland en Utrecht het eigenlijk erg vergelijkbaar doen. Het grote verschil is dat in Gelderland het maximale aantal rond de 80 lag, en in Utrecht rond de 160.
Zou dit het verschil in het gemiddelde kunnen verklaren? Inderdaad! Als we de gemeente in Utrecht met het getal rond de 160 weghalen, daalt het gemiddelde in Utrecht van 19,6 naar 14,0, erg vergelijkbaar met de 14,5 in Gelderland. De conclusie die we trokken uit het eerste figuur – dat er in Utrechtse gemeentes veel meer positieve coronatesten zijn dan in Gelderse – klopt dus niet met het genuanceerdere beeld dat hier tevoorschijn komt. Het gaat namelijk om een enkele gemeente waar het aantal besmettingen veel hoger ligt. Hoewel we onze conclusies over de provincie Utrecht niet moeten laten leiden door deze uitzondering, is zo’n opvallend hoog getal wel een goeie start om te gaan onderzoeken wat er in die gemeente precies aan de hand is en hoe de verspreiding van het coronavirus daar ingedamd kan worden.
Tot slot is het cruciaal om de onderliggende data van grafieken goed te begrijpen, voordat je conclusies kunt trekken. Bijvoorbeeld, om deze grafieken te interpreteren is het essentieel om te weten hoeveel mensen er eigenlijk wonen in de gemeentes en provincies, of hoeveel mensen er getest zijn. We moeten kritisch nadenken over zowel de onderliggende data als de grafieken.
Dus de volgende keer dat je een interessante grafiek tegenkomt, probeer dan te letten op wat er op de assen staat, en wees op je hoede als in een grafiek bepaalde informatie weggelaten is. Op die manier zul je minder makkelijk gefopt worden door misleidende grafieken.
Credits
Originele taal: Nederlands
Auteur: Marlijn ter Bekke
Buddy: Jeroen Uleman
Editor: Wessel Hieselaar
Vertaling: Ellen Lommerse
Editor vertaling: Mónica Wagner
Foto van Markus Winkler via Unsplash