This post is also available in .
Van het volhouden van een pijnlijke beklimming tot het genieten van het prachtige uitzicht op de top: kunstmatige intelligentie laat zien hoe het brein zichzelf een boost geeft.
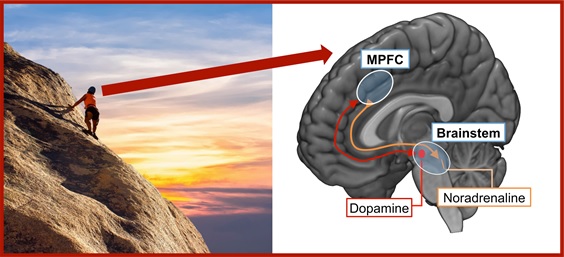
Foto van Pixabay (links), is aangepast en gecombineerd tot het gehele foto door Eliana Vassena and Massimo Silvetti. An klimmer is op weg naar de peak, terwijl het netwerk van de MPFC-hersenstam de afgifte van noradrenaline en dopamine reguleert zodat de klimmer de top bereikt.
Hoe blijven we doorgaan als we een berg beklimmen? Hoe kiezen we voor de kortste route omhoog zonder mooie vergezichten op te offeren? Dergelijke uitdagingen en beslissingen komen in het dagelijkse leven vaak voor en dankzij de evolutie heeft ons brein een briljante strategie gevonden ze op te lossen: door zichzelf een boost te geven.
Het uitoefenen van fysieke of mentale inspanning vereist hoge waarden van noradrenaline. Om te kunnen leren wanneer inspanningen leiden tot beloning (bijv., de beklimming en het uitzicht) heb je de juiste hoeveelheid dopamine nodig. Noradrenaline en dopamine zijn chemische substanties die worden losgelaten vanuit de hersenstam, een gebied diep onderin het brein. Vanuit de hersenstam bereiken ze de cortex, en dan met name de mediale prefrontale cortex(MPFC).
Wanneer we moeilijke beslissingen maken of ons voorbereiden ons in te spannen is de MPFC ook actief. Deze vondst heeft tot een nieuwe hypothese geleid: de MPFC en hersenstam werken misschien wel samen om in elke situatie de optimale niveaus van noradrenaline en dopamine te bepalen (bijv., om de top van de berg te bereiken). Zo zou de hersenstam de MPFC kunnen leren wanneer er meer inspanning nodig is (via uitscheiding van dopamine) en de MPFC kan dat vervolgens in praktijk brengen door een noradrenaline boost te vragen van de hersenstam.
Het brein begrijpen via computersimulaties
De complexiteit van de MPFC-hersenstam relatie en de grote hoeveelheid beschikbare data vormen een ingewikkelde puzzel, wat het lastig maakt om te begrijpen hoe de niveaus van noradrenaline en dopamine worden gecontroleerd en hoe ze gedrag beïnvloeden. Gelukkig komt de kunstmatige intelligentie ons te hulp door ons een efficiënte manier te bieden om data te interpreteren en deze nieuwe hypothese te testen. Onderzoekers hebben een computerprogramma gebouwd dat simulaties maakt van de hersenactiviteit in de MPFC en hersenstam en simuleert hoe noradrenaline en dopamine gedrag beïnvloeden. Dit programma, de Reinforcement Meta-Learner (RML), kan leren wat voor acties leiden tot waardevolle uitkomsten (beloningen) en oefent vervolgens de juiste hoeveelheid inspanning uit om deze acties succesvol uit te voeren (door noradrenaline-uitscheiding te simuleren).
Vertelt de RML ons echt hoe het brein leert beter zijn best te doen?
Om te begrijpen of de RML ons echt laat zien hoe MPFC-hersenstam interacties werken hebben onderzoekers de beslissingen van het RML-programma getest in situaties waar verschillende hoeveelheden van (cognitieve en fysieke) inspanning waren vereist om de taak goed uit te voeren en de beloning te ontvangen. Onderzoekers hebben ook de neurale activiteit gesimuleerd binnen het RML, specifiek in de MPFC en de hersenstam. Zowel de keuzes als de neurale activiteit van het RML-programma waren vergelijkbaar met wat was gevonden in mensen: zo vermeed de RML moeilijke taken tenzij er een grote beloning tegenover stond; daarbij was de MPFC meer actief in voorbereiding voor een inspannende vergeleken met een makkelijke taak, en de hersenstam liet een boost van noradrenaline zien. Deze resultaten bevestigen dat methoden van kunstmatige intelligentie zoals de RML succesvol hersenactiviteit en gedrag kunnen simuleren, wat het makkelijker maakt te onderzoeken hoe het brein beslissingen maakt en zich aanpast aan nieuwe uitdagingen.
Dit blog was geschreven door twee gastbloggers. Eliana Vassena werkt aan het Donders Instituut en onderzoekt hoe het brein motivatie en beslissingen ondersteunt om inspannend gedrag uit te voeren. Massimo Silvetti werkt aan het National Research Council in Rome en ontwikkelt computersimulaties van hersennetwerken. Beide onderzoekers hebben beurzen ontvangen van de Horizon 2020 -Marie Curie Actions.
Dit blog is gebaseerd op een artikel in Science Trendsen het wetenschappelijke artikel is gepubliceerd in het tijdschrift PLOS Computational Biology.
Aangepast door Mahur en Marisha, vertaald door Felix
Thanks a lot for the blog article.Much thanks again. Great.