This post is also available in Dutch.
From enduring the pain of a climb to enjoying stunning views from the top: artificial intelligence shows how the brain gives itself a boost.

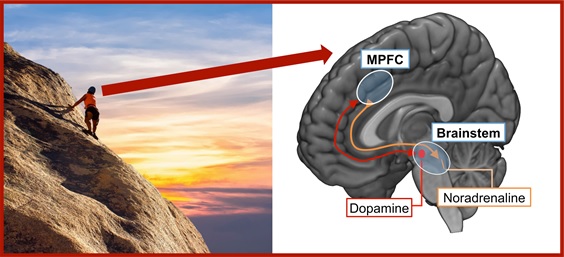
Image from Pixabay (left), adapted and combined to a full image by Eliana Vassena and Massimo Silvetti. A climber heading to the top of a mountain (left), while her
MPFC-brainstem system (right) controls how much noradrenaline and
dopamine must be released to optimize brain performance to reach the
top.
How do we keep going when hiking up a mountain? How do we choose the shortest path to the top without forgoing stunning views? This kind of challenges and decisions are very common in everyday life, and evolution provided our brain with a brilliant strategy to solve them: give itself a boost.
Exertion of physical or mental effort requires higher levels of noradrenaline. Learning when the effort will lead to a reward (for example, the climb to the view) requires the right amount of dopamine. Noradrenaline and dopamine are chemical substances released by the brainstem, a region deep down in the brain. From the brainstem, they reach the cortex, especially the medial prefrontal cortex (MPFC).
When we make difficult decisions, or prepare to exert effort, the MPFC is active as well. This evidence inspired a new hypothesis: MPFC and brainstem may be working together to determine the optimal level of noradrenaline and dopamine needed in any situation (e.g., to reach the top of the mountain). This way, the brainstem would help MPFC learn (via dopamine increase) when more effort is required, and the MPFC could turn that into practice by requesting a noradrenaline boost from the brainstem.
Understanding the brain through computer simulations
The complexity of MPFC-brainstem interactions and the large amount of available data form a very intricate puzzle, making it very challenging to understand how noradrenaline and dopamine levels are controlled and how they impact behaviour. Luckily, artificial intelligence comes to the rescue, providing an efficient way of interpreting data and testing this new hypothesis. Researchers have built a computer program that simulates the brain activity of the MPFC and the brainstem, and how noradrenaline and dopamine transmission influences behaviour. This program, called the Reinforcement Meta-Learner (RML), is able to learn what actions lead to valuable outcomes (rewards), and exerts sufficient effort to carry out these actions successfully (through simulation of noradrenaline release).
Does the RML really tell us how the human brain learns to try harder?
To understand whether RML really tells us how MPFC-brainstem interactions work, researchers have tested the decisions of the RML program in tasks where different levels of effort (both cognitive and physical) were required to complete successfully the jobs and receive a reward. Researchers also measured the neural activity simulated within the RML, especially of the MPFC and brainstem. Both the choices as well as the brain activity made by the RML program were similar to what was found in humans: for example, the RML avoided difficult tasks, unless a very large reward was at stake; furthermore, the MPFC was more active when preparing for an effortful as compared to an easy task, and the brainstem released a boost of noradrenaline. These results confirm that artificial intelligence methods such as the RML model successfully simulate brain activity and behaviour, thus helping to investigate how the brain makes decisions and adapts to new challenges.
This blog was written by two guest bloggers. Eliana Vassena works at the Donders Institute and studies how the brain supports motivation and decisions to engage in effortful behaviour. Massimo Silvetti works at the National Research Council in Rome, and develops computer simulations of brain networks. Both researchers obtained funding from the Horizon 2020 -Marie Curie Actions.
Thisblog is based on an article on Science Trends and the scientific paper is published in the journal Plos Computational Biology.