This post is also available in Dutch.
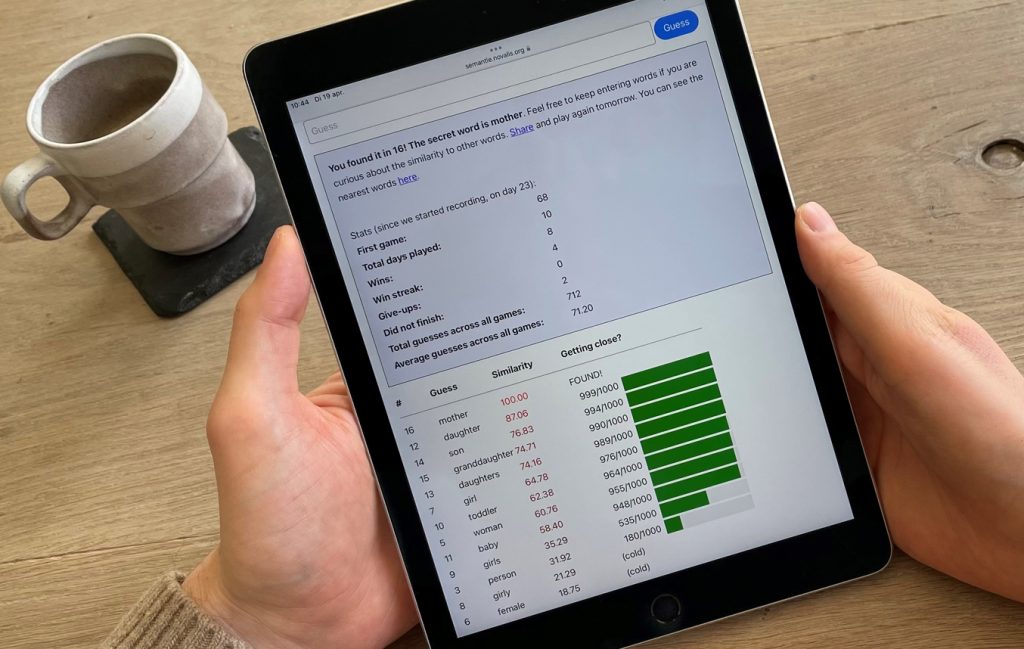
For a few weeks now, I’ve been obsessed with the game Semantle. The goal is to guess a secret word daily based on its meaning (also called semantics). With each guess, the game indicates the extent to which your guess has a similar meaning to the answer, using a score between -100 (your guess is very different from the answer) and 100 (your guess is the right answer). For example, if I were to type in my guess dog now, that word would get a similarity score of 2.20. This is quite low, so dog is not very similar to the answer. But how does a computer know how similar two words are?
How is the similarity calculated?
To calculate how similar two words are, the game uses an algorithm called Word2Vec. The main idea behind Word2Vec is that you can infer the meaning of a word from the words with which the word is often used together, just as you could assess someone based on their friends. Words with the same “friends” are likely to have similar meanings.
The Word2Vec algorithm uses a large number of texts to find connections between words and their “friends”. Each word is “translated” into a series of numbers based on the connections found, since computers cannot calculate with words, but only with numbers. Then the similarity between two words is calculated just like the difference between numbers: the closer together the numbers, the more similar the words.
Applications beyond the game
This particular way of making words understandable to computers was obviously not merely invented for this game, but has all kinds of useful applications. For example, it is used to improve computer translation software such as Google Translate as well as spam filters. What is also interesting is that based on these calculated similarities you can also predict language phenomena, for example, to what extent a word like cat activates another word like dog in our mental lexicon (the dictionary of our brain). It is a fascinating question whether the way computers learn and store the meaning of words might be similar to how our brain does it!
Smart Semantle tips
I highly recommend you to also try a game of Semantle or the special version Pimantle, where similarity is made visual in a kind of galaxy. Based on the underlying algorithm, I can give you 3 tips:
- Semantle’s algorithm learned the words and their relationships by reading newspapers, so typical newspaper words like politics or policy are often a good guess.
- The type of word also plays a role, e.g., a noun or a verb, because verbs often occur in similar contexts to other verbs (“I enjoy _”).
- Antonyms (e.g., hot and cold) have similar meanings to the algorithm because they occur in similar contexts (“The tea is too _”).
It’s a difficult game, so if you still can’t figure it out despite my tips, you can always check the Reddit forum for hints 🙂
Credits
Author: Marlijn ter Bekke
Buddy: Felix Klaassen
Editor: Wessel Hieselaar
Translation: Brittany van Beek
Editor translation: Ellen Lommerse
Image by Marlijn ter Bekke
Semdle, to some extent is similar to Semantle. Although, Semdle was conceived and developed independently without any prior knowledge of Semantle.
The following rules of Semdle makes it much simpler to play –
1. ??A starting hint is provided to steer the game
2. The remaining hints are progressively closer to the hidden word and selected from different parts of speech and context so as to give a holistic clue to the player e.g. if the hidden word is ‘server’, the clues could consist of both waiter / restaurant and computer / cloud
3. The % similarity score is logarithmic and helps player get closer to hidden word much faster
Hence, is most cases a player should be able to guess the hidden word using 5 hints and within 20 guesses (under 5 mins play time). Also, there are few implicit strategies that a player uncovers after few games and use less number of hints.
Cheers!