This post is also available in .
Again, the internet is divided over a viral meme: an audio clip where some hear “Yanny” and others, “Laurel.” Acoustics can help finally solve this puzzle for good.
The Laurel-Yanny audio clip was first discovered by a high school student who posted it to Instagram, but it quickly spread across social media.
A couple of weeks ago the internet was once again shaken by a meme that had everyone taking sides. While reminiscent of #TheDress, there’s one main difference: whereas “the dress” had people doubting their eyes, the latest viral meme is an audio clip. The controversy: some people swear they hear the name “Yanny” while others hear a clear “Laurel.”
Since the outbreak, it has been revealed that the original audio clip, from online dictionary Vocabulary.com, was of the word “laurel.” The clip is a recording of audio playing over PC speakers which introduced some distortion making the speech sound more ambiguous. So why do some people hear “Yanny”?
Hearing on a different frequency
In the midst of the Laurel-Yanny frenzy, many scientists have been called upon to answer this question (see this Twitter thread for a nice analysis). One of the first things they noticed was that it may have to do with frequency: people who hear “Laurel” hear a deep male voice while “Yanny”-advocates report a high-pitched voice.
Acoustic analysis of the audio clip reveals that it does have a lot of high frequency (high-pitched) noise, more than the original Vocabulary.com file. Below are spectrograms of the audio clip, along with those of another male voice saying “Laurel” and “Yanny,” for visualization.
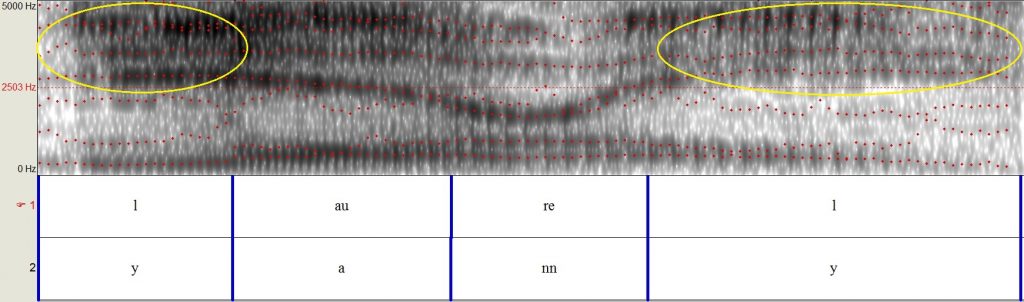
(1) Spectrogram of the original, ambiguous “Laurel-Yanny” audio clip.
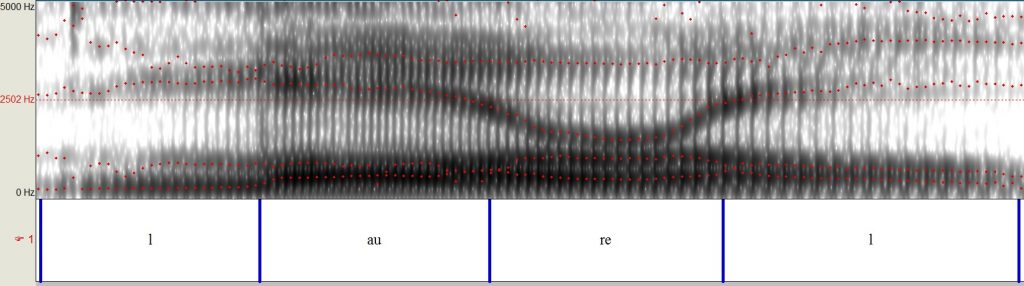
(2) Spectrogram of another male voice saying “Laurel.”
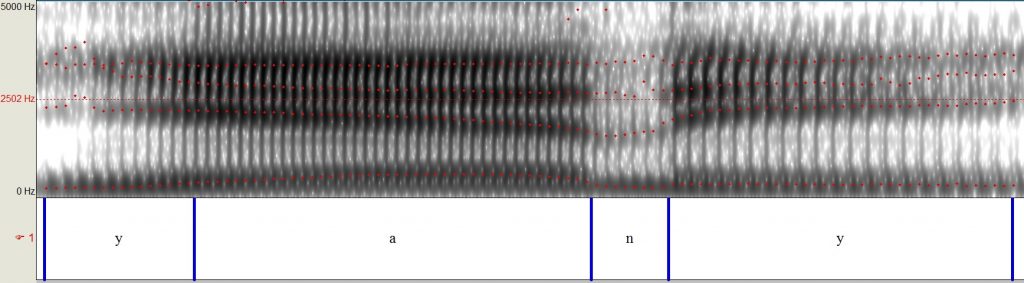
(3) Spectrogram of that same male voice saying “Yanny.”
A spectrogram is a visual representation of a sound, showing the different frequencies (y-axis) over time (x-axis). Difference in darkness shows the amplitude (or intensity) of the frequencies. If you compare the original audio clip (1) with that of another male saying “Laurel” (2), you’ll notice a greater presence (darker shades) of the high frequencies in the original clip, particularly at the beginning and end (yellow circles). The audio clip of someone saying “Yanny” (3) has similar high frequencies at these points, which explains why some people hear that.
But why do some people hear “Laurel” and others “Yanny”? And why can some hear both, and switch between them? The short answer: because the sound is ambiguous.
Ambiguity leaves room for interpretation
Our brains are always trying to interpret reality based on cues and are amazing at filtering information to select the most important cues. In this case, though, how you filter these cues can make you conclude different things.
As the spectrograms show, the brain has to process a lot of information to decipher speech. As it turns out, people can actually vary a lot in what acoustic cues they pay attention to, or even what frequencies they’re most sensitive to. The Laurel-Yanny audio clip is interesting because, although the words seem very different, acoustically the sounds being confused actually aren’t that different: which frequency band you emphasize makes all the difference. If you emphasize the higher frequencies it spells out the word “Yanny,” while emphasizing the lower frequencies gives you “Laurel.” In the figures below, the dots trace the dominant frequency bands in the audio clip. Highlighted in yellow are frequencies a listener might be paying attention to in order to hear that word.
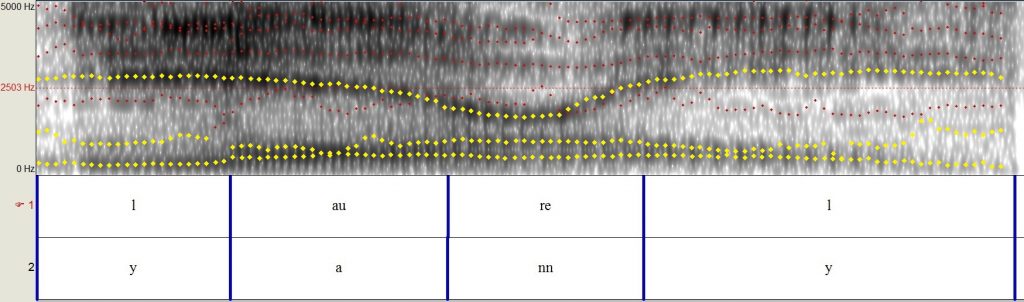
(4) In yellow: the frequency bands that someone hearing “Laurel” might be emphasizing. Notice that the ‘l’ sound at the beginning of the word is made up of two lower frequencies and a higher one, as in (2).
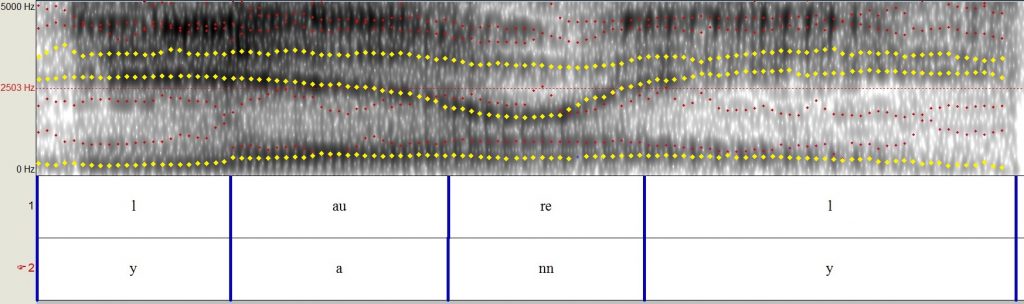
(5) In yellow: the frequency bands that someone hearing “Yanny” might be emphasizing. Notice how the frequencies at the beginning of the word have changed. Instead of one of the weaker lower frequencies in ‘l’, people who hear “Yanny” focus on the two more dominant high frequencies, as in (3).
This just goes to show that both words can technically be heard in the sound file, so there’s no need to get up in arms with people who hear differently than you… although that’s what social media is for, after all.
This blog was written by Monica Wagner, edited by Annelies van Nuland.
For a similar but perhaps even more mind-boggling illusion, check out the newest viral meme: Brainstorm/Green needle.
Spectrograms were created using PRAAT.