This post is also available in .
Het internet is wederom verdeeld over een viral meme: een geluidsopname waarin sommigen “Yanny” horen en anderen “Laurel.” De akoestiek kan ons helpen deze puzzel op te lossen.
Het Laurel-Yanny fragment was ontdekt door een leerling op een middelbare school die het vervolgens op Instagram had geplaatst, maar al snel verspreidde het over de gehele social media.
Een aantal weken geleden was er weer eens tumult rondom een meme die iedereen in kampen leek te verdelen. Het doet al snel denken aan #TheDress, maar er is een groot verschil: waar “de jurk” mensen liet twijfelen aan hun ogen, betreft het dit keer een audiofragment. De kwestie: sommige mensen zweren dat ze de naam “Yanny” horen terwijl anderen overduidelijk “Laurel” verstaan.
Sindsdien is het gebleken dat de originele audioclip, afkomstig van online woordenboek Vocabulary.com, hoorde bij het woord “laurel” (lauwerkrans) De clip is een opname van audio die wordt afgespeeld via computer speakers, waardoor het geluid vervormd wordt en de uitspraak erg onduidelijk is. Maar waarom horen sommigen dan “Yanny”?
Een andere frequentie horen
Tijdens de Laural-Yanny discussie werd aan veel wetenschappers gevraagd om duidelijkheid te verschaffen (zie dit Twittergesprek voor een goede analyse). Een van de eerste dingen die ze opvielen was dat het misschien iets te maken heeft met frequentie: mensen die “Laurel” horen, horen een diepe mannelijke stem, terwijl de mensen van kamp “Yanny” juist zeggen een hoge stem te horen.
Akoestische analyse van het audio fragment laat zien dat het inderdaad een hoop extra tonen in de hoge frequentie (hoge tonen) heeft, meer dan in het originele Vocabulary.com bestand. Hieronder zie je de spectogrammen van de audio clip, samen met die van een andere mannelijke stem die “Laurel” en “Yanny” zegt, ter visualisatie.
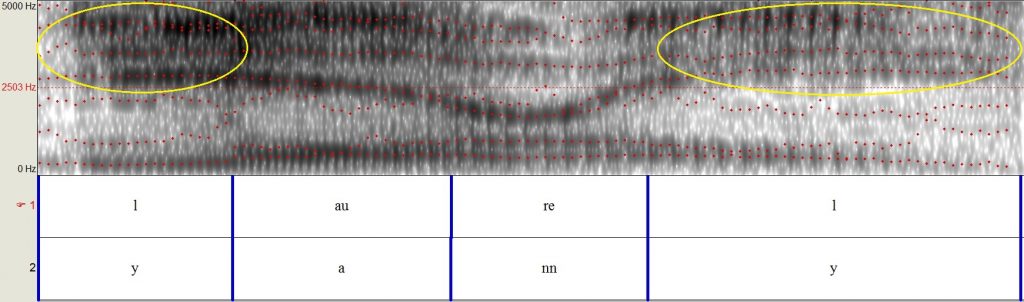
(1) Spectogram van het originele, onduidelijke, “Laurel-Yanny” geluidsfragment.
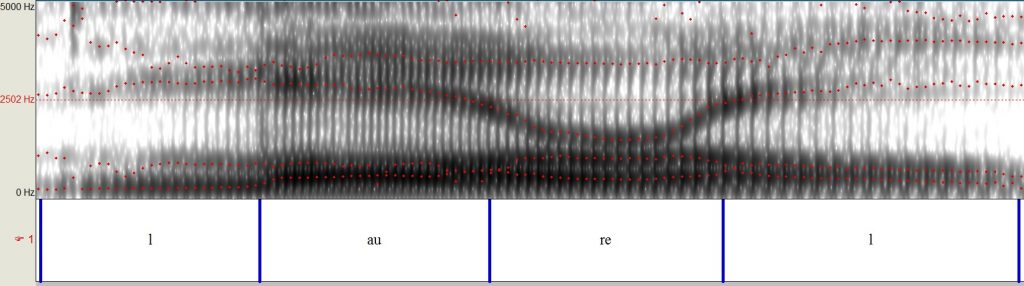
(2) Spectogram van een andere mannelijke stem die “Laurel” zegt.
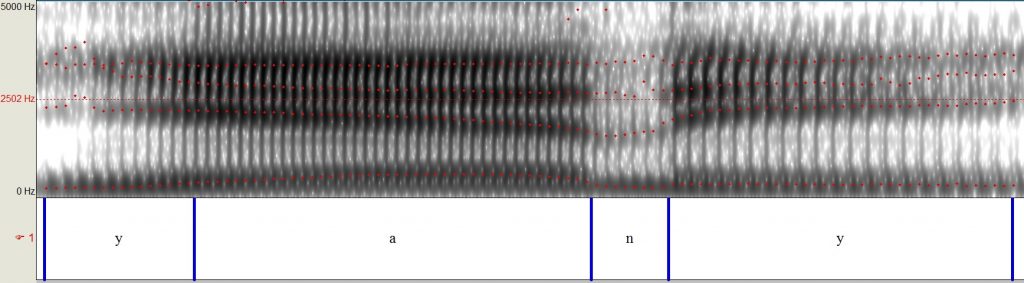
(3) Spectogram van diezelfde mannelijke stem die “Yanny” zegt.
Een spectogram is een visuele representatie van geluid die verschillende frequenties (y-as) laat zien over tijd (x-as). Verschillen in de donkerheid laten de amplitude (of intensiteit) van de frequenties zien. Als je de originele audioclip (1) vergelijkt met die van een andere man die “Laurel” (2) zegt, zal je zien dat er een grotere aanwezigheid (donkerdere tinten) is van hogere frequenties in de originele clip, met name in het begin en aan het einde (gele cirkels). De audioclip van iemand die “Yanny” zegt (3) heeft vergelijkbare hoge frequenties op deze plekken, wat verklaart hoe sommige mensen dat horen.
Maar waarom horen sommige mensen “Laurel” en anderen “Yanny”? En waarom kunnen sommigen zelfs beide horen, en zelfs wisselen tussen de twee? Het korte antwoord is: omdat het geluid onduidelijk (ambigu) is.
Ambiguïteit geeft ruimte voor interpretatie
Onze hersenen proberen altijd de werkelijkheid te interpreteren op basis van aanwijzingen en zijn extreem goed in het filteren van informatie om de meest belangrijke aanwijzingen te selecteren. In dit geval kan de manier waarop dit wordt gefilterd echter leiden tot afwijkende conclusies.
Zoals de spectogrammen laten zien moet het brein een hoop informatie verwerken om spraak te ontrafelen. En wat blijkt nou; mensen kunnen erg verschillen in wat voor akoestische kenmerken ze op letten, of zelfs voor welke specifieke frequenties ze het meest gevoelig zijn. De Laurel-Yanny clip is interessant omdat, hoewel de woorden erg verschillend lijken, akoestisch gezien de verwarde geluiden helemaal niet zo verschillen: de specifieke frequenties die jij als luisteraar benadrukt maken het verschil. Als je de nadruk legt op de hogere frequenties hoor je “Yanny”, terwijl als je meer op de lagere frequenties focust je eerder “Laurel” zal horen. In de figuren hieronder zie je stipjes die de dominantie frequenties in het signaal aangeven. In geel zijn de frequenties waarop iemand focust om dat specifieke woord te horen.
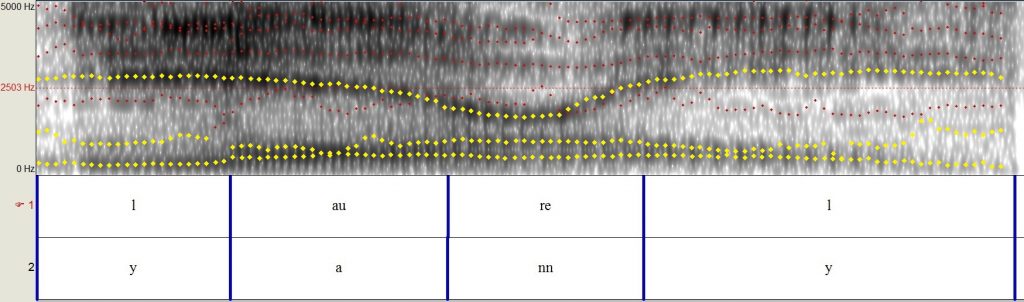
(4) In geel: de frequenties waar iemand die “Laurel” hoort op focust. Zie dat het ‘l’ geluid aan het begin van het woord bestaat uit twee lagere frequenties en een hogere, net als in (2).
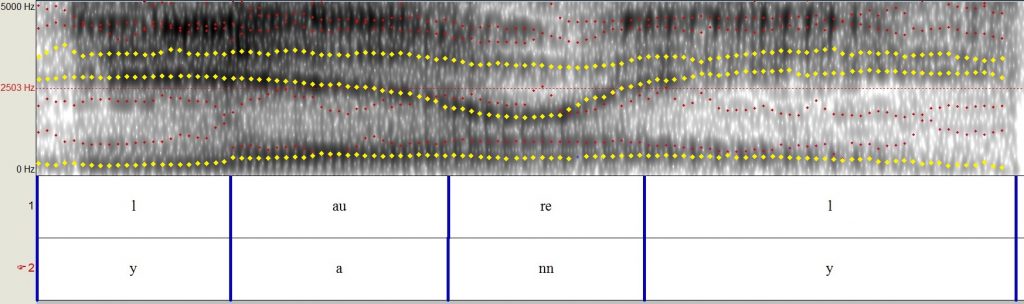
(5) In geel: de frequenties waar iemand die “Yanny” hoort op focust. Zie hoe de frequenties in het begin van het woord zijn veranderd. In plaats van te focussen op een van de twee zwakkere en lagere frequenties in ‘l’, focussen de “Yanny”-mensen meer op de twee dominante hoge frequenties, net als in (3).
Dit laat zien dat technisch gezien beide woorden gehoord kunnen worden in het geluidsbestand, dus het is niet nodig in strijd te gaan met mensen die iets anders horen dan jij… alhoewel social media daar wel voor gemaakt zijn.
Deze blog is geschreven door Monica Wagner, aangepast door Annelies van Nuland en vertaald door Felix Klaassen.
Nieuwsgierig naar een vergelijkbare maar misschien nog wel gekkere illusie? Zoek dan naar de nieuwste viral meme: Brainstorm/Green needle.
Spectogrammen zijn gemaakt met behulp van PRAAT.